-
Home Lab SSD Encryption
Recently I rebuilt a home server which acts as a NAS for my personal data. I wanted to make sure the data would be secure in the event of the server being stolen, ideally with:
- Reasonably secure encryption (targeted attacks will get the data one way or another)
- Low performance overhead, since the machine isn’t high spec
- The ability to be unlocked remotely in the event of a power outage
Solution
Once I started to consider different options, I was surprised to discover that not only are almost all modern SSDs actually “Self-Encrypting Drives” (SEDs) - meaning that they come with support for hardware full-disk encryption - but that this encryption is always active. From ArchWiki:
Read MoreIn fact, in drives featuring full-disk encryption, data is always encrypted with the data encryption key when stored to disk, even if there is no password set (e.g. a new drive). Manufacturers do this to make it easier for users who do not wish to enable the security features of the self-encrypting drive. These self-encrypting drives can be thought of as having a zero-length password by default that always transparently encrypts the data (similar to how passwordless SSH keys can provide somewhat secure access without user intervention).
-
Exportify Refresh
Way back in 2015 I released the first version of Exportify, a small web application for exporting / backing up Spotify playlists to CSV format for safekeeping (click here to go straight to the app if you’d like to try it).
It’s fair to say I’ve rather neglected this project over the past few years, so I decided to spend a good chunk of time this November on adding new features, fixing bugs and improving robustness, as well as a complete overhaul of the React dev stack.
Read More
-
Discovering MSW
Recently, as part of a development stack refresh for Exportify, I found myself digging around for the best approach to mocking HTTP requests in a JS test suite.
I needed something that would play nicely with Jest and React, allow me to mock requests at the transport layer so my tests could be de-coupled from the HTTP request library I chose to use, as well as of course providing a convenient DSL for writing the tests themselves.
Read More -
GooglePlacesAutocomplete CocoaPod
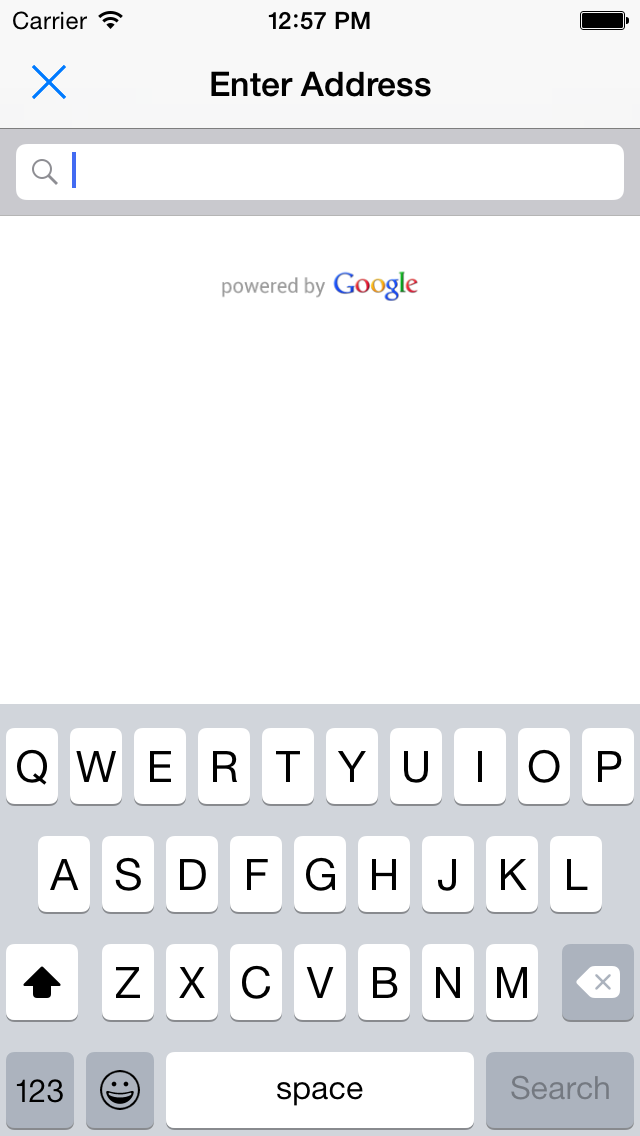
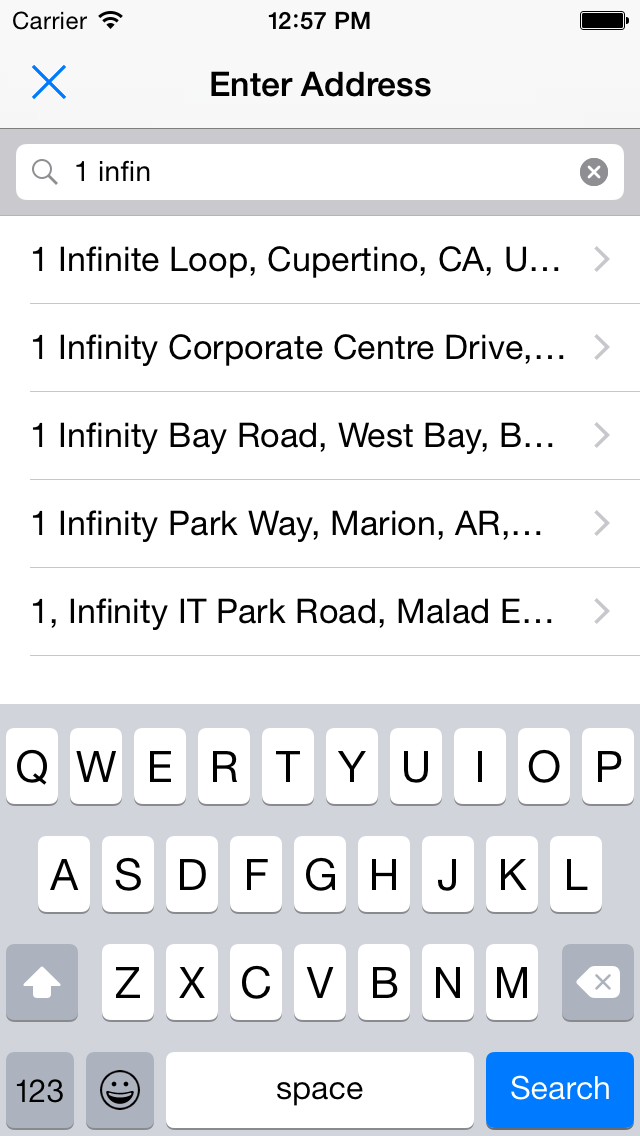
GooglePlacesAutocomplete is a simple Google Places API autocompleting address entry view for iOS devices, written in Swift.
There are already a couple of solutions out there for this. GooglePlacesAutocomplete is different because it is 100% Swift, and aims to provide the simplest possible method of entering validated, autocompleted addresses.
It’s available as a CocoaPod - installation instructions here. Feedback and contributions welcome!
Screenshots
-
Ruby speech recognition with Pocketsphinx
pocketsphinx-ruby is a high-level Ruby wrapper for the pocketsphinx C API. It uses the Ruby Foreign Function Interface (FFI) to directly load and call functions in libpocketsphinx, as well as libsphinxav for recoding live audio using a number of different audio backends.
The goal of the project is to make it as easy as possible for the Ruby community to experiment with speech recognition, in particular for use in grammar-based command and control applications. Setting up a real time recognizer is as simple as:
configuration = Pocketsphinx::Configuration::Grammar.new do sentence "Go forward ten meters" sentence "Go backward ten meters" end Pocketsphinx::LiveSpeechRecognizer.new(configuration).recognize do |speech| puts speech endThis library supports Ruby MRI 1.9.3+, JRuby, and Rubinius. It depends on the current development versions of Pocketsphinx and Sphinxbase - there are Homebrew recipes available for a quick start on OSX.
